Method
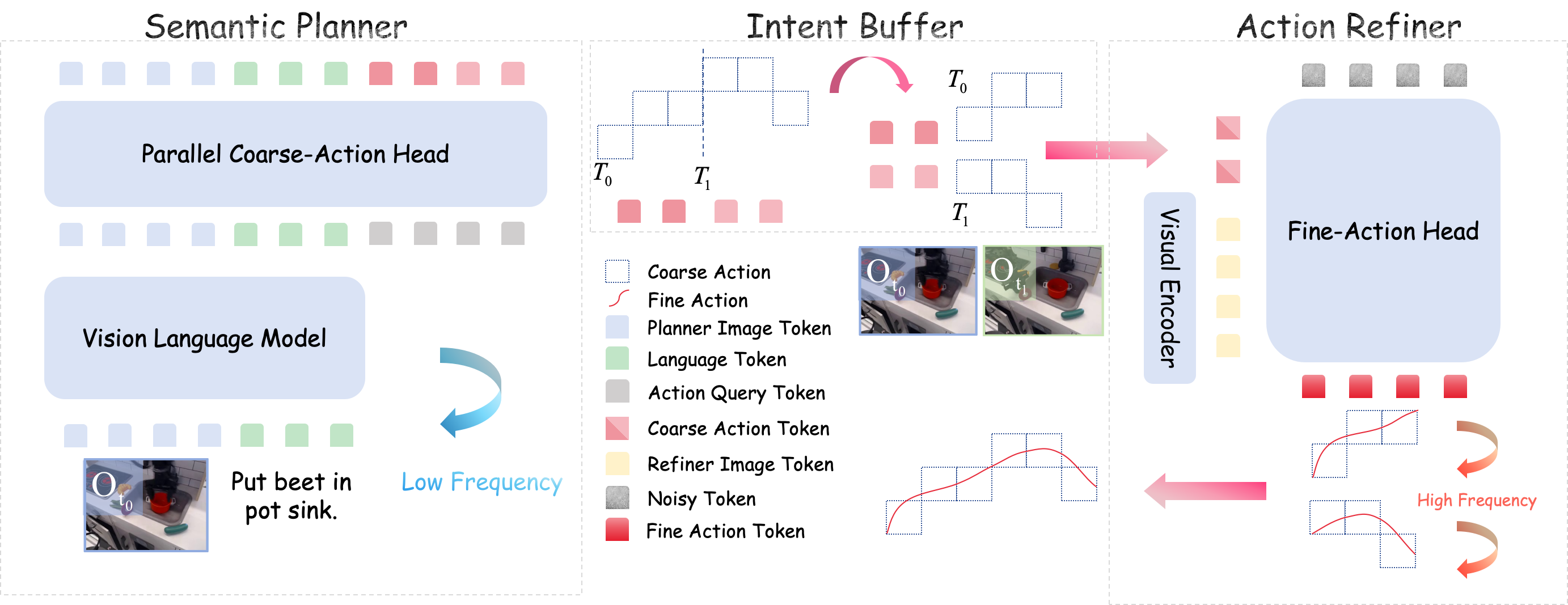
We factorize the joint policy distribution into two conditional stages. The Semantic Planner (System 2) leverages a pre-trained VLM to predict coarse directional tokens via a Parallel Coarse-Action Head, trained with Cross-Entropy loss. To align physical control with the VLM's semantic space, we discretize normalized continuous actions into N uniform bins. These discrete tokens serve as coarse actions representing macro-directional intents rather than precise kinematics, naturally aligning with the VLM's semantic reasoning capabilities.
The Action Refiner (System 1) operates as a conditional diffusion policy that refines the coarse intent into executable precise motions. To furnish fine-grained visual representations for precise actuation while achieving structural decoupling, the Fine-Action Head is augmented with an independent visual encoder to extract geometric features. The Fine-Action Head conditions on the composite input of noisy actions, geometric features, and macro-intent embeddings to iteratively reverse the diffusion process.
The asynchronous execution strategy further decouples inference costs: the Semantic Planner predicts an extended macro-horizon Lmacro = M × Hchunk in a single pass, filling an intent buffer (FIFO queue). The Action Refiner then operates at high frequency by consuming buffered intents, significantly reducing average inference latency.